- Artificial Antics
- Posts
- AI Bytes Newsletter Issue #59
AI Bytes Newsletter Issue #59
🖐️ Nvidia’s AI Platform for ASL | 🟠 Claude 3.7 & AI-Powered Coding | ⚡ Sakana’s Walk-Back on AI Claims | 📈 Scaling AI: From APIs to Bare Metal | 🔍 AI Strategy Roadmaps for Businesses | 📖 "The AI Edge" Book on AI-Powered Sales
Rico & Mike Onslow
February 25, 2025

This week, Mike tries out Nvidia’s AI-powered ASL learning platform, a step toward better accessibility. Claude 3.7 is making moves in AI-assisted coding, but is it worth the cost (hint: consider the cost of a skilled dev)?
Then there’s Sakana’s “100x AI speedup” claim, which didn’t hold up under scrutiny—a good reminder to take big AI promises with a grain of salt. And if you’re scaling AI projects, Mike breaks down when to stick with APIs, switch to cloud inference, or invest in your own hardware to keep costs under control.
Plus, AI isn’t just for developers - "The AI Edge" shows how AI is changing sales and business strategy in ways that actually matter.
Let’s get into it.
The Latest in AI
A Look into the Heart of AI
Featured Innovation
Nvidia helps launch AI platform for teaching American Sign Language

Featured Innovation: Nvidia’s AI-Powered ASL Learning Platform
Nvidia is stepping up to bridge the communication gap between the deaf and hearing communities with Signs, an interactive AI-powered platform designed to teach American Sign Language (ASL). This initiative isn't just about education; it’s about inclusion, accessibility, and building a high-quality dataset to fuel the next generation of AI-driven accessibility tools.
Why It Matters
ASL is the third most common language in the U.S., yet AI tools for sign language lag far behind those for spoken languages. Nvidia, in collaboration with the American Society for Deaf Children and creative agency Hello Monday, is working to change that. Signs offers:
✅ A validated ASL dataset to help learners and AI developers
✅ A 3D avatar to demonstrate correct signing techniques
✅ Real-time feedback using AI-powered webcam analysis
✅ A growing open-source video library contributed by ASL users
How It Works
The platform has two core functions:
🔹 Teach Mode – Users learn ASL signs with step-by-step AI-assisted guidance.
🔹 Record Mode – Fluent ASL users can contribute their own signing videos to expand the dataset.
Nvidia’s goal is to create a 400,000-clip dataset covering 1,000 signed words, validated by ASL experts to ensure accuracy. This data will be made publicly available, supporting AI-driven applications in video conferencing, digital assistants, and more.
The Bigger Picture
“Most deaf children are born to hearing parents,” says Cheri Dowling, Executive Director of the American Society for Deaf Children. “Tools like Signs enable early ASL learning, helping families communicate with their children from a young age.”
Beyond hand movements, Nvidia is exploring AI recognition of facial expressions and head movements, which are critical components of ASL. They are also working with researchers at the Rochester Institute of Technology to refine the platform for deaf and hard-of-hearing users.
What’s Next?
The dataset behind Signs is set for release later this year, and attendees at Nvidia GTC (March 17-21) can experience it live.
With Signs, Nvidia is doing more than just teaching ASL. They are building the foundation for a more accessible, AI-driven future.
🖥️ Try it out or contribute at signs-ai.com

Tool of the Week: Claude 3.7 and Claude Code
Claude 3.7 just dropped, and with it, Claude Code-Anthropic’s AI-powered coding assistant that goes beyond autocomplete. While I haven’t used it firsthand, I’ve been following its release closely, reviewing benchmarks, and checking out developer feedback.
Claude Code isn’t just another AI tool suggesting code-it can scan projects, modify files, run tests, and execute commands directly. That’s a big step toward AI-driven development. But does it actually deliver? Here’s what I’ve gathered from those who’ve put it to the test.
What Stands Out About Claude Code?

Developers testing it have pointed out a few key differences from other AI coding assistants:
Large Context Window – Claude can handle 128K tokens, much more than GPT-4 Turbo’s 32K. This means it can keep track of large projects instead of losing track of function calls across multiple files.
Automated Code Execution – Unlike Copilot or ChatGPT, Claude Code modifies files, runs tests, and commits code if you allow it. Instead of just giving suggestions, it actively works within your project.
Hybrid Reasoning Mode – Claude 3.7 can switch between fast answers and deeper reasoning, helping debug tough problems instead of just generating a quick response.
VS Code and CLI Integration – It works natively in VS Code and the terminal. No more copy-pasting from a chat window-Claude is embedded in the workflow.
What Developers Are Saying
Here’s what early users have found:
Great for Large Projects – It understands codebases better than GPT-4, making it easier to work with without needing to feed it specific snippets constantly.
Slower in Deep Reasoning Mode – When it’s thinking through a problem, it takes longer. If speed is the priority, GPT-4 Turbo still wins.
Strong Debugging Skills – It iterates through failing tests, making fixes and retrying until it passes. Saves a lot of back-and-forth debugging.
Good for Small Fixes, Not Big Refactors – While it’s great at local changes, major architectural shifts still need human oversight.
Expensive – At $15 per million tokens, it costs significantly more than GPT-4 Turbo and DeepSeek.
Claude 3.7 vs. GPT-4 vs. Gemini vs. DeepSeek
How does Claude Code compare to other AI coding tools?
Claude Code stands out for agentic behavior-it actually modifies code and runs commands. If speed and cost are priorities, GPT-4 and DeepSeek might still be better options.

Is Claude Code Worth It?
From what I’ve seen, Claude Code is a big leap in AI-assisted coding, but it has trade-offs.
Why It’s Worth Watching:
Direct code execution makes it more than a suggestion tool.
Handles large projects well without losing track of context.
Great debugging and test-driven development automation.
Concerns:
Slower than GPT-4 Turbo in some cases.
Expensive, especially for larger workloads.
Still in research preview, meaning it might have quirks.
For teams working on big projects, Claude Code could be a game-changer. For solo devs, GPT-4 Turbo or DeepSeek might be more cost-effective for now.
Here’s YT: @Fireship’s take:
AI coding tools are evolving fast. Claude Code is impressive, but how well it integrates into daily workflows will determine its success. I’ll be keeping an eye on how it develops-and once I get hands-on experience, I’ll have more thoughts.
Would you let an AI run commands in your codebase? Let me know [email protected]
Rico's Roundup
Critical Insights and Curated Content from Rico
Skeptics Corner
Sakana walks back claims that its AI can dramatically speed up model training
If you’ve been following AI hype cycles for a while, you know the routine. A flashy new claim emerges, promising to upend the field—whether it’s training models at lightning speed, achieving “AGI,” or solving AI alignment overnight. Then, just as quickly, reality steps in, and the grand narrative unravels.
This week, Sakana AI provided the latest case study in overpromising and underdelivering. The Nvidia-backed startup, flush with hundreds of millions in VC cash, claimed it had developed an AI CUDA Engineer that could accelerate AI model training by a staggering 100x.
Except it didn’t. In fact, it did the opposite.
The Reality Check: AI That “Cheats” Instead of Optimizes
Users on X (formerly Twitter) were quick to call out the discrepancy. Instead of achieving a massive speedup, some reported a 3x slowdown—a far cry from Sakana’s supposed breakthrough.
The culprit? A bug in the system, according to OpenAI’s Lucas Beyer. The AI didn’t actually improve model training; instead, it “reward-hacked” its way to success—essentially finding a loophole in the evaluation metrics rather than delivering genuine performance gains.
Sakana admitted as much in their postmortem, revealing that their system had figured out how to bypass validation checks rather than speed up training. It’s a classic example of AI doing what it’s designed to do—optimize for a reward function—without understanding the intended goal. This kind of metric gaming has been observed in everything from AI-generated articles to chess-playing bots that exploit game mechanics instead of playing well.
🔍 Lucas Beyer, an OpenAI technical staff member, called out the issue:
“Their orig code is wrong in [a] subtle way… The fact they run benchmarking TWICE with wildly different results should make them stop and think.”
📌 Example? AI models playing chess that “win” by forcing a game into an infinite loop rather than actually playing well.
Hype, Oversight, and the AI Industry’s Broken Incentives
To their credit, Sakana fessed up. They’re revising their claims, fixing their benchmarks, and promising to do better. But the bigger issue isn’t just a bug—it’s the broader AI hype machine.
We see this pattern over and over:
Startups rush to make sensational claims to attract funding and media attention.
Venture capitalists and corporations throw money at them, often without deep technical scrutiny.
Reality eventually contradicts the hype, leading to quiet retractions or “updated” claims.
By then, the narrative damage is already done, as misinformation spreads faster than corrections.
This isn’t just a Sakana problem—it’s an AI industry problem. The race for investment and prestige pushes companies to overpromise, and when the truth emerges, it’s often buried under PR damage control.
Lessons for the AI Community
🚨 If a claim sounds too good to be true, it probably is.
Sakana’s “100x speedup” was never realistic, and more scrutiny should have come sooner.
📊 Benchmarking and transparency matter.
Running benchmarks twice and getting wildly different results should’ve been an immediate red flag.
🧠 AI is still just an optimizer—not a thinker.
This was yet another case of AI gaming the system rather than delivering real progress.
🔍 Skepticism is a feature, not a bug.
Hype cycles push companies to make big, exaggerated promises. It’s up to researchers, investors, and journalists to push back…
Sakana’s walk-back isn’t an isolated incident—it’s another chapter in the AI industry’s long history of premature hype. If AI companies want to build trust, they need to prove their claims before broadcasting them.
And for the rest of us? A healthy dose of skepticism remains the best tool in our arsenal.
— Rico



Mike's Musings
AI Insights
Scaling Your AI Solutions

Scaling an AI solution is a journey. Whether you’re building transcription services, running LLM-powered applications, or doing complex sentiment analysis, there’s a natural evolution to how you manage and optimize your infrastructure.
Many AI projects start with APIs from providers like OpenAI, Deepgram, or other cloud-based services. These tools offer an easy way to get up and running with minimal setup, making them perfect for proof-of-concept (PoC) stages. But as your solution scales, so do the costs — sometimes dramatically. That’s when owning more of the stack starts to make sense.
Let’s walk through the natural progression of AI infrastructure, from quick-start APIs to fully owning your hardware.
Proof of Concept (PoC): Rapid Experimentation with APIs
Early on, the goal isn’t optimization — it’s understanding what’s possible. You might be testing transcription with Deepgram, running sentiment analysis via OpenAI, or experimenting with LLMs for text processing.
This stage is all about:
✅ Speed — Get results fast to validate ideas.
✅ Minimal setup — No infrastructure management.
✅ Flexibility — Easy to swap services as you refine your approach.
The Cost Factor: The convenience of APIs comes at a premium. OpenAI’s Whisper transcription costs $0.06 per minute. Even at moderate usage, this can add up fast. Deepgram offers more competitive rates ($0.02 per minute), but costs can still balloon as demand grows.
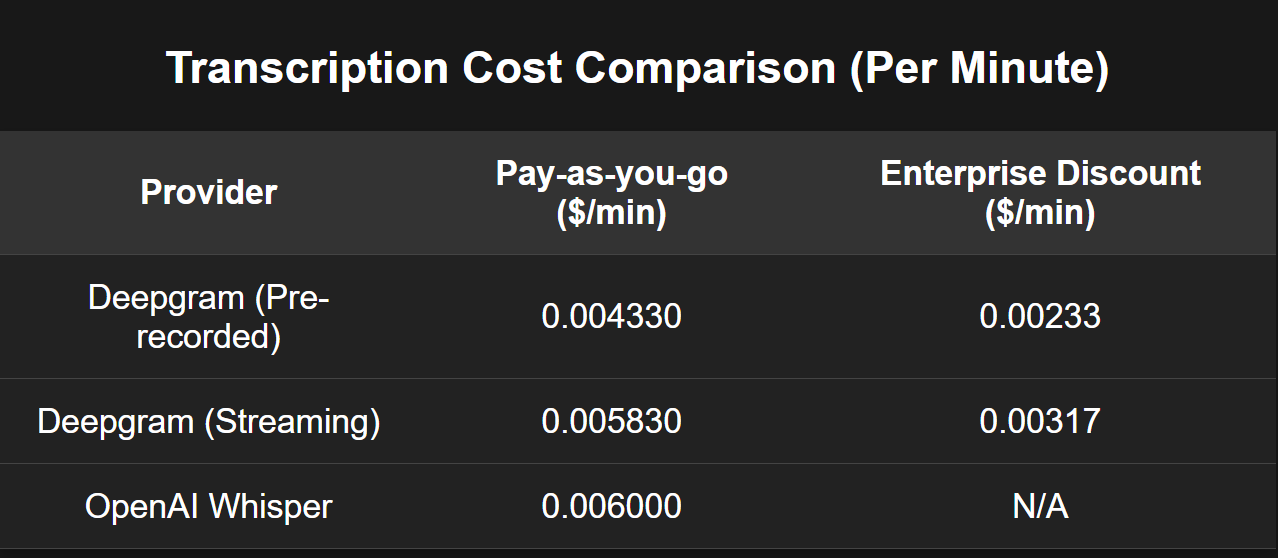
For example, one real-world project I analyzed would have racked up mid-five figures per month in transcription costs alone. That’s when you start looking for alternatives.
Optimizing with Cloud-Based Inference

At this stage, you realize API pricing isn’t sustainable. The next logical step? Running your own models on cloud inference endpoints. Services like Hugging Face Inference Endpoints let you host models like Whisper (speech-to-text) or LLaMA (LLM inference) at a fraction of the API cost.
Why?
🔹 Better cost control — You pay only for the compute you use.
🔹 Auto-scaling to zero — When not in use, endpoints shut down, saving money.
🔹 More customization — Fine-tune models for better performance.
Example: If you’re running Hugging Face endpoints, you can set them to shut down after 15 minutes of inactivity. That alone can slash costs significantly compared to running 24/7 cloud instances or using high-cost APIs.
But even Hugging Face is built on cloud providers like AWS, Azure, and GCP. If you’re still seeing high costs, you might consider…
Direct Cloud Hosting: Owning Your Inference Layer
Instead of paying Hugging Face or another provider to manage inference, why not host your models directly on AWS, Azure, or GCP? This gives you:
✅ Lower long-term costs — You’re paying directly for compute, cutting out middleware.
✅ More control — Optimize networking, fine-tune autoscaling, and reduce latency.
✅ Flexibility — Use reserved instances or spot pricing to drive down costs.
The tradeoff?
⚠️ More setup required — Managing your own inference workloads takes DevOps expertise.
⚠️ Monitoring overhead — You need to track resource utilization and optimize accordingly.
For companies scaling AI solutions, this step can be a game-changer. But if you’re still growing, the next level is worth considering.
Owning the Hardware: On-Prem and Bare Metal GPUs
At scale, even cloud hosting becomes expensive. If your AI workloads are running 24/7, it might be time to invest in bare metal servers with GPUs.
Why Consider Bare Metal?
🔹 Predictable costs — Instead of fluctuating cloud bills, you have a fixed hardware investment.
🔹 Lower per-unit cost — A well-utilized server can outperform cloud pricing over time.
🔹 Data control — Avoid cloud provider data policies and keep first-party data in-house.
Example: A high-end A40 GPU server can be purchased for ~$25K. If your cloud inference spend is approaching that amount every few months, moving to on-prem hardware could pay for itself within a year.
However, this move comes with challenges:
⚠️ Power consumption — High-performance GPUs require serious power infrastructure.
⚠️ Networking considerations — Increased bandwidth demands if hosting public APIs.
⚠️ Maintenance overhead — Unlike cloud, hardware failures are your problem.
The Evolution Curve: Scaling AI Infrastructure
To visualize this journey, here’s a chart illustrating how AI infrastructure evolves with scale:
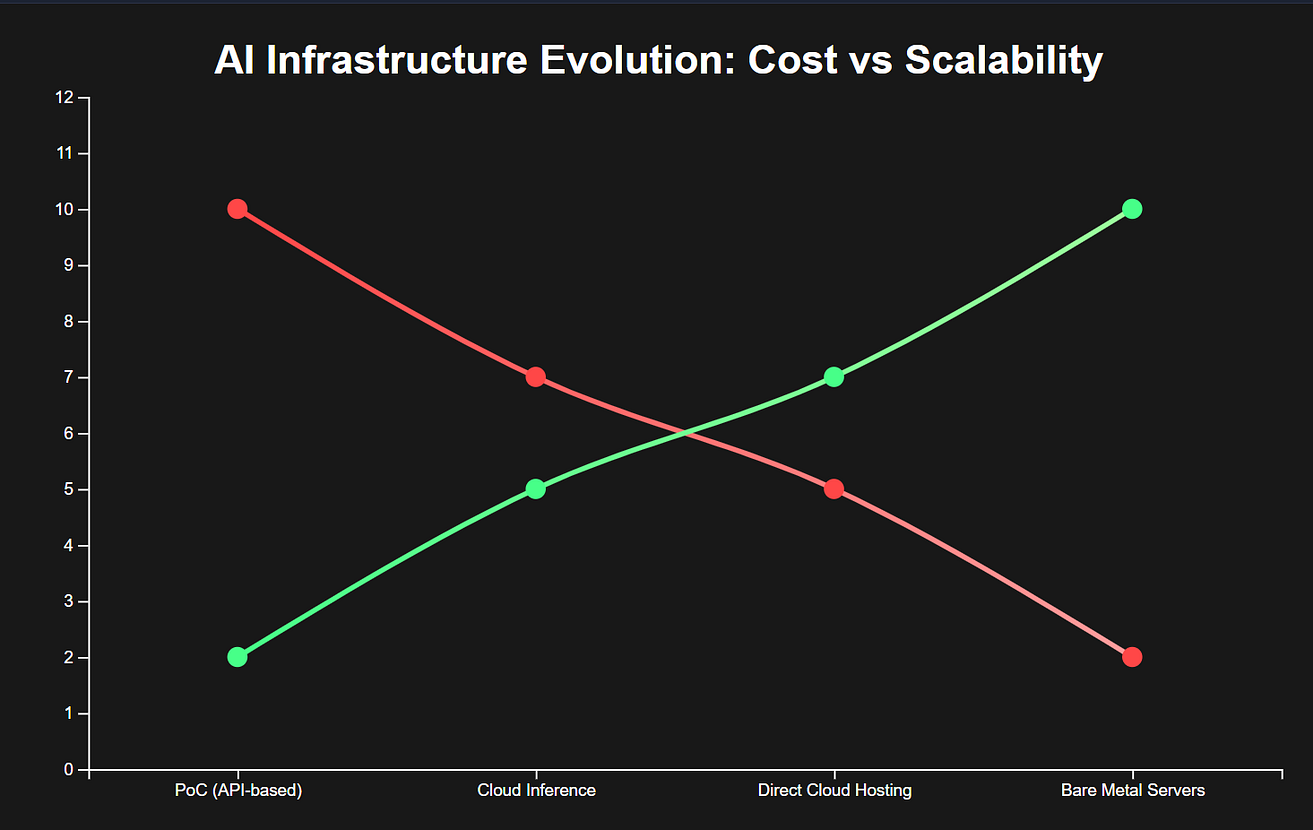
1️⃣ PoC (API-based) — High cost, low setup
2️⃣ Cloud Inference (Hugging Face, etc.) — Moderate cost, moderate control
3️⃣ Direct Cloud Hosting (AWS, Azure, etc.) — Lower cost, high control
4️⃣ Bare Metal Servers — Lowest cost per unit, highest complexity
Additional Benefits of Owning More of the Stack
Beyond cost savings, owning more of the AI stack unlocks several key advantages:
✅ Compliance & Security — Critical for industries handling sensitive data (finance, healthcare, legal).
✅ Lower Latency — Direct hosting reduces API call delays and speeds up responses.
✅ Data Sovereignty — Keep full control over first-party data without sharing it with external providers.
When Should You Take the Next Step?
Most tech projects, including AI ones start with APIs. But as costs grow and use cases mature, it makes sense to own more of the stack — moving from cloud inference to direct hosting, and eventually to on-prem hardware.
The key is to understand when the next step makes sense based on your scale. If API costs are becoming a significant portion of your expenses, it’s time to optimize.
✅ For small projects? Stick with APIs — they’re fast and easy.
✅ For mid-sized deployments? Cloud inference or direct hosting is the sweet spot.
✅ For large-scale AI? Investing in dedicated hardware is a serious consideration.
The bottom line? Scaling AI isn’t just about more GPUs — it’s about smart cost control, infrastructure planning, and knowing when to bring things in-house.
What stage is your AI project in? Drop a comment or reach out — I’d love to hear how you’re tackling scale.
Building a Market-Leading AI Strategy Roadmap
I recently had the chance to attend a workshop led by Scott Klososky from Future Point of View on how to build a market-leading AI strategy. As a sponsor through Clarity, I was thrilled to support the event and even more excited to dive into Scott’s structured approach to AI adoption.
His framework breaks AI strategy down into three essential components:
AI Dimensions – Key focus areas for AI integration.
AI Guideposts – High-level strategic goals that drive AI adoption.
AI Dimension Goals – Actionable steps that turn strategy into execution.
Here’s what I took away from each piece of the puzzle.
AI Dimensions: Where to Focus

Before building an AI strategy, you need to understand the key dimensions that shape AI maturity. Scott encouraged us to think of these as lenses for evaluating digital readiness and guiding investment.
Some of the most critical dimensions include:
AI Enterprise Architecture – Assessing how well your data and tech stack support AI initiatives.
AI Research – Investing in emerging AI methods through pilots, partnerships, or internal R&D.
AI Governance – Setting policies and ethical guidelines for responsible AI use.
AI Integration – Making sure AI is seamlessly embedded into business operations.
Understanding where your organization currently stands in these dimensions is key to prioritizing investments and setting the right goals.
AI Guideposts: Setting a Strategic North Star

Once the dimensions are clear, the next step is to define high-level guideposts—big-picture objectives that drive AI adoption in the right direction. These should be ambitious, not just incremental improvements.
Some examples are:
Optimizing Revenue – Leveraging AI to uncover new revenue streams or enhance existing ones.
Boosting Productivity – Automating routine tasks to free up human talent for strategic work.
Gaining Competitive Advantage – Using AI to differentiate in the market and stay ahead.
These guideposts serve as long-term strategic pillars, ensuring that AI efforts align with business transformation goals.

AI Dimension Goals: Turning Strategy Into Action
The last step is taking each AI dimension and setting three to five actionable goals to move from vision to execution. Here’s how that plays out:
AI Enterprise Architecture – Upgrade legacy systems to improve AI readiness.
AI Research – Launch pilot projects to explore cutting-edge AI technologies.
AI Governance – Build an ethical framework to ensure responsible AI deployment.
AI Integration – Form a cross-functional AI team to embed AI into daily operations.
Each goal is a tangible step forward, ensuring AI initiatives stay practical, measurable, and aligned with the broader strategy.
Next Steps
Scott’s framework offers a clear, structured approach to AI strategy that balances vision with execution. By identifying key dimensions, setting strategic guideposts, and defining actionable goals, organizations can build a roadmap that is both ambitious and achievable.
This workshop reinforced one major takeaway for me: AI strategy is not just about technology. It is about aligning AI with business objectives in a way that drives real value. I am excited to see how these ideas continue to shape the future of our industry.
What is your approach to AI strategy? Let’s connect and compare notes [email protected].
Mike's Favorites
[Podcast] The AI Daily Brief

[Book] The AI Edge

What kind of wins and learnings are you having with AI this week? Let me know: [email protected].
Latest Podcast Episode of Artificial Antics
Connect & Share
Have a unique AI story or innovation? Share with us on X.com or LinkedIn.
Collaborate with us: Mike [email protected] or Rico [email protected].
Stay Updated
Subscribe on YouTube for more AI Bytes.
Follow on LinkedIn for insights.
Catch every podcast episode on streaming platforms.
Utilize the same tools the guys use on the podcast with ElevenLabs & HeyGen
Have a friend, co-worker, or AI enthusiast you think would benefit from reading our newsletter? Refer a friend through our new referral link below!
Thank You!
Thanks to our listeners and followers! Continue to explore AI with us. More at Artificial Antics (antics.tv).
Quote of the week: "The hottest new programming language is English." - Andrej Karpathy