- Artificial Antics
- Posts
- Scaling AI Solutions

Scaling an AI solution is a journey. Whether you’re building transcription services, running LLM-powered applications, or doing complex sentiment analysis, there’s a natural evolution to how you manage and optimize your infrastructure.
Many AI projects start with APIs from providers like OpenAI, Deepgram, or other cloud-based services. These tools offer an easy way to get up and running with minimal setup, making them perfect for proof-of-concept (PoC) stages. But as your solution scales, so do the costs — sometimes dramatically. That’s when owning more of the stack starts to make sense.
Let’s walk through the natural progression of AI infrastructure, from quick-start APIs to fully owning your hardware.
Proof of Concept (PoC): Rapid Experimentation with APIs
Early on, the goal isn’t optimization — it’s understanding what’s possible. You might be testing transcription with Deepgram, running sentiment analysis via OpenAI, or experimenting with LLMs for text processing.
This stage is all about:
✅ Speed — Get results fast to validate ideas.
✅ Minimal setup — No infrastructure management.
✅ Flexibility — Easy to swap services as you refine your approach.
The Cost Factor: The convenience of APIs comes at a premium. OpenAI’s Whisper transcription costs $0.06 per minute. Even at moderate usage, this can add up fast. Deepgram offers more competitive rates ($0.02 per minute), but costs can still balloon as demand grows.
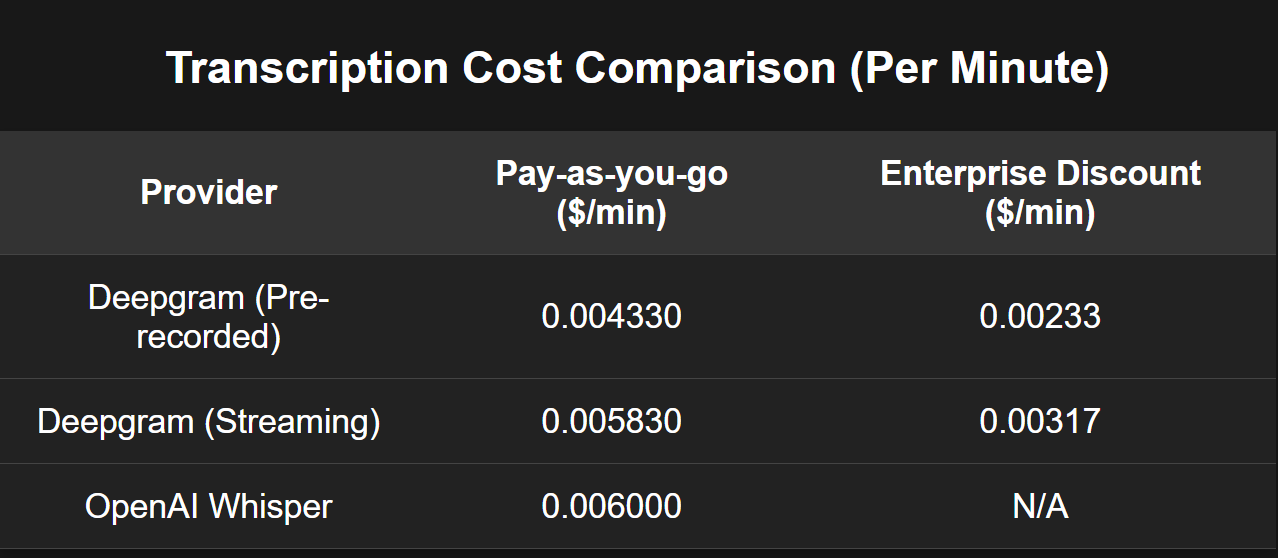
For example, one real-world project I analyzed would have racked up mid-five figures per month in transcription costs alone. That’s when you start looking for alternatives.
Optimizing with Cloud-Based Inference

At this stage, you realize API pricing isn’t sustainable. The next logical step? Running your own models on cloud inference endpoints. Services like Hugging Face Inference Endpoints let you host models like Whisper (speech-to-text) or LLaMA (LLM inference) at a fraction of the API cost.
Why?
🔹 Better cost control — You pay only for the compute you use.
🔹 Auto-scaling to zero — When not in use, endpoints shut down, saving money.
🔹 More customization — Fine-tune models for better performance.
Example: If you’re running Hugging Face endpoints, you can set them to shut down after 15 minutes of inactivity. That alone can slash costs significantly compared to running 24/7 cloud instances or using high-cost APIs.
But even Hugging Face is built on cloud providers like AWS, Azure, and GCP. If you’re still seeing high costs, you might consider…
Direct Cloud Hosting: Owning Your Inference Layer
Instead of paying Hugging Face or another provider to manage inference, why not host your models directly on AWS, Azure, or GCP? This gives you:
✅ Lower long-term costs — You’re paying directly for compute, cutting out middleware.
✅ More control — Optimize networking, fine-tune autoscaling, and reduce latency.
✅ Flexibility — Use reserved instances or spot pricing to drive down costs.
The tradeoff?
⚠️ More setup required — Managing your own inference workloads takes DevOps expertise.
⚠️ Monitoring overhead — You need to track resource utilization and optimize accordingly.
For companies scaling AI solutions, this step can be a game-changer. But if you’re still growing, the next level is worth considering.
Owning the Hardware: On-Prem and Bare Metal GPUs
At scale, even cloud hosting becomes expensive. If your AI workloads are running 24/7, it might be time to invest in bare metal servers with GPUs.
Why Consider Bare Metal?
🔹 Predictable costs — Instead of fluctuating cloud bills, you have a fixed hardware investment.
🔹 Lower per-unit cost — A well-utilized server can outperform cloud pricing over time.
🔹 Data control — Avoid cloud provider data policies and keep first-party data in-house.
Example: A high-end A40 GPU server can be purchased for ~$25K. If your cloud inference spend is approaching that amount every few months, moving to on-prem hardware could pay for itself within a year.
However, this move comes with challenges:
⚠️ Power consumption — High-performance GPUs require serious power infrastructure.
⚠️ Networking considerations — Increased bandwidth demands if hosting public APIs.
⚠️ Maintenance overhead — Unlike cloud, hardware failures are your problem.
The Evolution Curve: Scaling AI Infrastructure
To visualize this journey, here’s a chart illustrating how AI infrastructure evolves with scale:
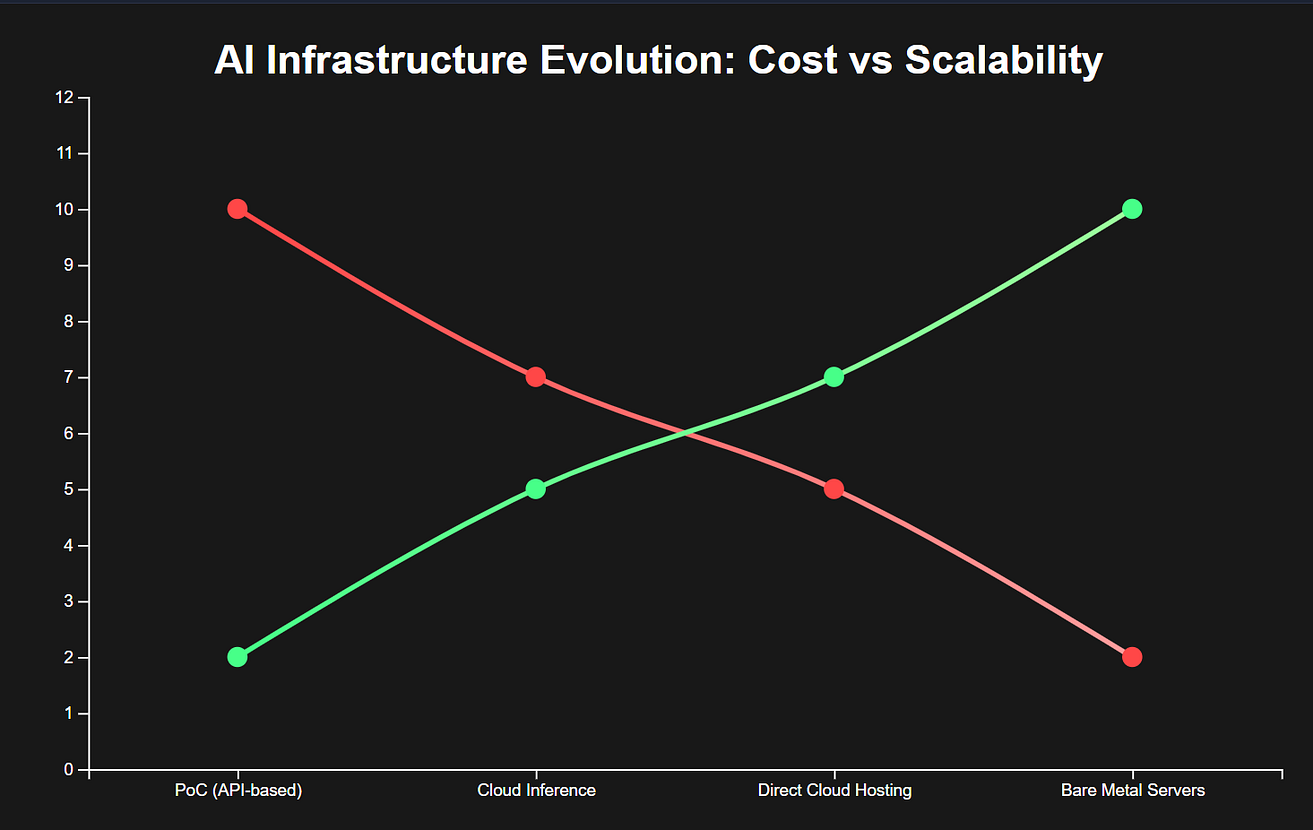
1️⃣ PoC (API-based) — High cost, low setup
2️⃣ Cloud Inference (Hugging Face, etc.) — Moderate cost, moderate control
3️⃣ Direct Cloud Hosting (AWS, Azure, etc.) — Lower cost, high control
4️⃣ Bare Metal Servers — Lowest cost per unit, highest complexity
Additional Benefits of Owning More of the Stack
Beyond cost savings, owning more of the AI stack unlocks several key advantages:
✅ Compliance & Security — Critical for industries handling sensitive data (finance, healthcare, legal).
✅ Lower Latency — Direct hosting reduces API call delays and speeds up responses.
✅ Data Sovereignty — Keep full control over first-party data without sharing it with external providers.
When Should You Take the Next Step?
Most tech projects, including AI ones start with APIs. But as costs grow and use cases mature, it makes sense to own more of the stack — moving from cloud inference to direct hosting, and eventually to on-prem hardware.
The key is to understand when the next step makes sense based on your scale. If API costs are becoming a significant portion of your expenses, it’s time to optimize.
✅ For small projects? Stick with APIs — they’re fast and easy.
✅ For mid-sized deployments? Cloud inference or direct hosting is the sweet spot.
✅ For large-scale AI? Investing in dedicated hardware is a serious consideration.
The bottom line? Scaling AI isn’t just about more GPUs — it’s about smart cost control, infrastructure planning, and knowing when to bring things in-house.
What stage is your AI project in? Drop a comment or reach out — I’d love to hear how you’re tackling scale.
Latest Podcast Episode of Artificial Antics
Connect & Share
Have a unique AI story or innovation? Share with us on X.com or LinkedIn.
Collaborate with us: Mike [email protected] or Rico [email protected].
Stay Updated
Subscribe on YouTube for more AI Bytes.
Follow on LinkedIn for insights.
Catch every podcast episode on streaming platforms.
Utilize the same tools the guys use on the podcast with ElevenLabs & HeyGen
Have a friend, co-worker, or AI enthusiast you think would benefit from reading our newsletter? Refer a friend through our new referral link below!
Thank You!
Thanks to our listeners and followers! Continue to explore AI with us. More at Artificial Antics (antics.tv).
Quote of the week: "Public AI models are like public toilets" - Tim Hayden